SMACK是一個由Spark, Mesos, akka, Cassandra, Kafka這五種技術來處理大數據的技術,各個技術有各自的角色和優點,最重要的技術我想就是Spark了,Spark比Hadoop可以更即時的處理各項資料,比如串流或是互動式,比Hadoop的批次方式更快速的分析和處理資料。
先簡單介紹一下各個技術
Spark
快速且通用的運算引擎在分散式、大量規模的資料處理上
Mesos
叢集資源管理系統提供資源的隔離和分享給各個分散式應用上
akka
一個工具集來建立高並發、分散式和可靠的訊息驅動的應用在JVM上
Cassandra
分散式、高可用的資料庫,設計來處理大量資料在不同資料中心上
Kafka
高吞吐量、低延遲、分散式的訊息系統,設計來處理實時資料處理
其實,其中幾個技術,Spark, Mesos, Kafka都有人寫成一個鐵人30天的文章了,有興趣可以自已去看查看細節,我目前主要是先簡單講一下架構,先有個關念這樣。
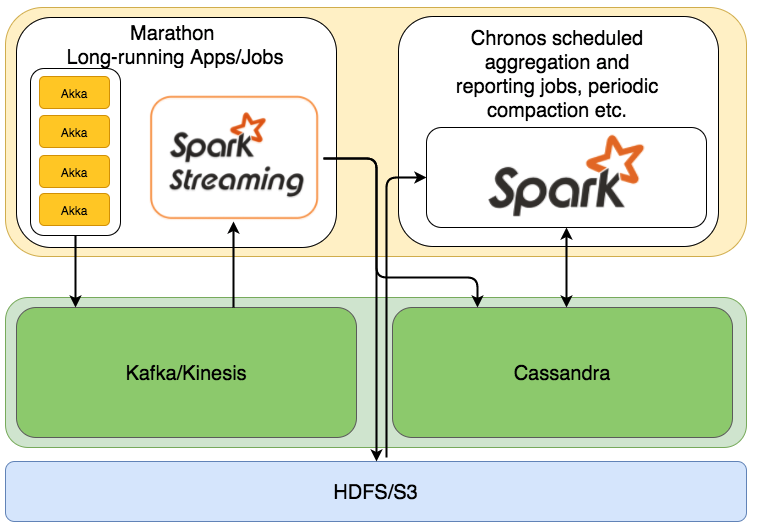
這張圖是從參考資料[1]取得的,用圖來解說,會更容易理解,首先akka是比較像是資料收集的角色,讓我們可以大量從前端接受資料,Kafka是有點拿來當暫存的角色,當Spark的運算核心掛了,或是來不及處理的時候,能暫時存放資料,而Spark就是資料處理的角色,但,其實Spark會分成批次和是即時處理的部分,而Spark的資料來源可能是Kafka或是Cassendra,Cassandra可以當成是資料庫角色,比較特別的是Mesos的角色,會負責Cassandra和Spark的資源分配,會盡量需要讓需要讀取的的Cassendra Node和Spark運算Node在同一個Node上(Node可以當作是一台機器)。其實各個技術有其優點和特色,如果有獨立研究,再作介紹。再來我會試著先簡單實作看看。
參考資料
Data processing platforms architectures with SMACK: Spark, Mesos, Akka, Cassandra and Kafka
Data processing platforms architectures with Spark, Mesos, Akka, Cassandra and Kafka
What is SMACK(Spark, Mesos, Akka, and Kafka)?



 iThome鐵人賽
iThome鐵人賽